摘要:論述了北京市天然氣日負荷的特點、預測模型的建立及優化過程。實現了智能動態預測,提高了預測模型的準確度和可信度。
關鍵詞:天然氣日負荷;負荷預測;實時優化
Real-time Optimization Forecast System of Natural Gas Daily Load in Beijing City
LI Chi-iia,LIU Yan,SHAO Zhen-yu
Abstract:The characteristics of natural gas daily load,the establishment and the optimization process of the forecast model for Beijing City are described.The intelligept dynamic forecast is realized,and the accuracy and reliability of the forecast model are improved.
Key words:natural gas daily load;load forecast;real-time optimization
日負荷預測的準確性關系到城市的供氣安全、穩定及經濟性,意義十分重大[1]。本文根據北京市天然氣日負荷變化特點,在分時段采用合適的預測模型基礎上,利用創新的實時優化系統,對預測模型進行實時優化后再預測,提高了預測模型準確度和可信度。
1 北京市天然氣日負荷特點
北京市大量天然氣要用于供暖,一年中用氣結構發生顯著變化,造成全年用氣極不均勻,年高峰日用氣量相當于低峰日用氣量的8倍左右。結合北京市溫度變化及用氣結構的時段變化特性,經過分析,北京市日負荷可以分為3個時段,即供暖期(當年11月15日至次年3月15日)、供暖過渡期(當年10月25日至11月14日及次年3月16日至3月31日)及用氣平穩期(當年4月1日至10月24日)。不同的時段對應著不同的負荷變化規律。在供暖期大量天然氣用于供暖,負荷主要受溫度影響,變化較大。供暖過渡期主要指自主供暖用戶的陸續開始或結束期間,表現出負荷急劇增加或減少。用氣平穩期用氣負荷變化不大,目前北京市夏季天然氣制冷用戶用氣量比例還很小,對總負荷變化影響也較小。
2 負荷預測模型的確定
北京市天然氣負荷受用氣結構、氣象因素、節假日、隨機因素等影響,全年用氣極不均勻。對于北京市供暖期負荷變化明顯不同于非供暖期的特殊情況,完全有必要根據不同時段的特性,研究使用不同的預測方法。不可能采用一種模型就可以使全年每天的負荷預測都取得較好的準確度。
綜合分析目前常用的各種預測方法并結合北京市負荷變化的特點,基本確定了包括神經網絡、時間序列、線性回歸這3種預測方法[2~6],以預測對應的各時段負荷。
對于供暖期,其主要影響因素是平均溫度及近幾天負荷。經計算得,近年來供暖期日負荷與日平均溫度及前2d的負荷相關系數相當大。供暖期適合用線性回歸模型預測。近年來供暖過渡期對應時期變化規律趨于一致,適合參照歷史變化信息與當前主要影響因素建立神經網絡模型預測,樣本選取一定量的前2年同期數據及預測日近20d左右的數據,最后訓練學習并預測。1年中用氣平穩期日用氣量變化不大,可看作一個隨時間變化的平穩時間序列,經差分處理后非常適合于用時間序列ARMA模型建模預測。
3 負荷預測模型優化
城市天然氣負荷一直在動態變化中,分時段確定的負荷預測模型并不能適應天然氣的發展。同一時段其主要影響因素也在動態變化,例如各個供暖期內的前5個影響因素就經常發生變化,即使同一供暖期主要影響因素在不同時間段也不盡相同。同一預測方法的建模變量數、樣本量選取及參數都將影響到預測模型的準確度。提高模型的預測準確度并能讓軟件分析計算出最優模型參數,并給出最優預測值,是預測軟件實用化的必然要求,也只有這樣才能從根本解決預測準確度問題。為此,本文創建了預測模型評估與實時優化系統。
3.1 預測模型評估
預測模型學習方法的泛化性能涉及它在獨立的檢驗數據上的預測能力。在實踐中,泛化性能評估尤為重要,它指導學習方法或模型的選擇,并為我們提供最終選定模型的質的度量[7]。
由訓練樣本估計的預測模型對應的樣本誤差為:
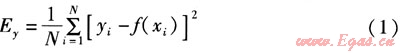
式中Ey——由訓練樣本估計的預測模型對應的樣本誤差
N——訓練樣本的數量
i——訓練樣本編號
yi——訓練樣本中對應輸入變量xi的目標變量
f——由訓練樣本估計的預測模型
xi——訓練樣本輸入變量
模型泛化誤差是指預測模型在獨立于訓練樣本的新數據上的期望預測誤差。我們需要確定泛化誤差的大小,而樣本誤差顯然不能作為泛化誤差的估計值。隨著訓練步數的增加,模型的復雜度提高,擬合優度提高,可以使得樣本誤差減小到0,然而樣本誤差為0的模型由于過分擬合訓練數據,泛化性能通常很差。擬合優度的高低并不能用來判斷建立模型的好壞。只有泛化誤差的大小才能評估預測模型的優劣。
因此,通常將建模數據分成3部分:訓練樣本集、驗證集和檢驗集。訓練樣本集用于擬合模型,驗證集用來估計模型的預測誤差,檢驗集用來評估最終選定的模型的泛化誤差。但是在實際應用中,模型的泛化誤差只有在進行了預測且預測結果實際發生后才能知道,而此時知道了預測誤差并沒有多大意義,這是因為知道實際結果前,我們就需要根據預測數據進行決策。因此要找到一種根據樣本或檢驗數據的誤差來估計泛化誤差的實用方法。
目前估計泛化誤差最簡單且最廣泛使用的方法是交叉驗證。這種方法直接估計樣本外誤差。通常將數據分成大致相等的k部分,k一般取5或10,對于第k部分,用其他的k-1部分擬合建立模型預測第k部分數據,從而計算擬合模型的泛化誤差。
泛化誤差的交叉驗證估計如下:
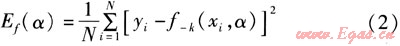
式中Ef(α)——模型f-k(xi,α)泛化誤差的交叉驗證估計
α——預測模型的調整參數
f-k(xi,α)——去掉了第七部分數據后的樣本估計的由參數OL調整的預測模型
3.2 實時優化系統
通過分析北京市天然氣日負荷數據,發現負荷變化受其最近幾天的負荷變化影響最大。根據“近大遠小”的規律并結合交叉驗證理論,模型優化系統求預測模型泛化誤差估計值時,人為地為預測日期的前2d加上了較大的權值,其權值參照預測日期近段時間內實際預測模型誤差進行適應性調整。本文以式(3)計算模型最優參數。
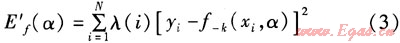
式中E′f(α)——引入調整權值后的模型f-k(xi,α)泛化誤差的交叉驗證估計
λ(i)——與目標變量yi相對應的權值,由模型評優模塊根據歷史預測結果實際誤差確定
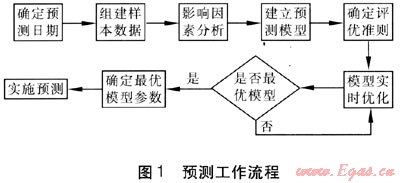
其工作過程如下:分析當前需要預測日期前幾天負荷及歷史同期負荷變化情況,實時分析近期主要影響因素,作為模型輸入變量。對建模樣本數、是否考慮星期及節假日影響、模型主要變量數及模型結構參數等尋優。相當于建立廠一系列不同的模型,根據歷史預測結果與實際結果的誤差大小確定評優準則及相應的權值,由式(3)計算得出誤差平方和最小時對應的預測模型參數,再以評估確定的最佳模型進行預測。當預測結果的真值出現后,進一步對預測結果進行后評價及誤差統計,為下一步預測時確定或修正評優準則提供依據。預測工作流程見圖1。
4 日負荷預測結果
北京市天然氣日負荷預測系統由可視化編程語言VB基于MATLAB數值計算軟件和SQL Server2000數據庫環境混合編程開發完成。系統結構采用CS(客戶端-服務器)結構,即數據庫安裝在服務器上,應用程序安裝在各臺電腦上,應用程序通過ODBC訪問數據庫。用戶只需安裝應用程序便可實現對燃氣負荷的預測、指標統計以及用戶信息等操作。開發的負荷預測系統,經過在不同時段自動選擇不同的預測模型,并采用模型實時優化系統得出最佳預測模型。表1是北京市2006年3月16日至2007年10月31日共595d的天然氣日負荷的預測統計結果。表1中︱δ︱表示相對誤差絕對值。
表1 天然氣日負荷預測統計結果
|
相對誤差范圍
|
所占比例/%
|
相對誤差范圍
|
所占比例/%
|
|
︱δ︱<1%
|
23.87
|
5%≤︱δ︱<7%
|
11.26
|
|
1%≤︱δ︱<2%
|
22.18
|
7%≤︱δ︱<10%
|
4.54
|
|
2%≤︱δ︱<3%
|
15.80
|
︱δ︱≥10%
|
1.85
|
|
3%≤︱δ︱<5%
|
20.50
|
—
|
—
|
可以看出,預測結果相對誤差絕對值小于5%者占總天數的82.35%,大于10%者占總天數的1.85%。計算得到595d的預測結果的相對誤差絕對值平均值為2.95%,總體情況較好。但最大相對誤差達26.2%,調查發現是因一些大用戶突然啟停等造成負荷突然大幅度變化而造成,如2006年6月24日用氣量為459.6×104m3/d,而6月25日突降為350.1×104m3/d,造成預測相對誤差為26.2%。2006年8月7日用氣量為367.0×104m3/d,而8月8日突增為507.1×104m3/d,預測相對誤差為-19.7%。燃氣公司若切實掌握大用戶的用氣計劃情況,對相應的預測值進行必要的修正,則效果會更好。
5 結論
在分時段采用不同的預測模型的基礎上,利用模型實時優化系統自動計算出最優模型參數進行預測,使預測模型能主動學習并跟隨天然氣負荷規律變化,解決了以前負荷預測模型不能適應城市天然氣發展變化的矛盾,大大提高了預測模型智能化程度,預測準確度也有明顯提高,且更加穩定可靠,是解決天然氣日負荷預測問題的一條新途徑。
在軟件智能預測的基礎上,掌握一些大用戶突然變化情況并結合專家的寶貴知識及經驗,適當對預測結果進行必要的修正,可以一定程度上解決預測軟件的不足。另外,進一步研究優化學習規則,并加入更多的預測模型,在實時智能優化系統這一平臺下,將有效地提高負荷預測準確度和可靠度。
參考文獻:
[1] 席德粹,焦文玲,李持佳,等.上海市燃氣負荷預測系統的開發與試驗運行[J].城市燃氣,2004,(7):14-16.
[2] 焦文玲,崔建華,廉樂明,等.城市燃氣短期周期負荷預測的時序模型[J].天然氣工業,2002,(1):92-94.
[3] 李持佳,焦文玲,朱建豪,等.基于人工神經網絡的春節期間燃氣負荷預測[J].煤氣與熱力,2004,24(9):477-480.
[4] 嚴銘卿,廉樂明,焦文玲,等.燃氣負荷及其預測模型[J].煤氣與熱力,2003,23(5):259-266.
[5] 焦文玲,朱寶成,馮玉剛.基于BP神經網絡城市燃氣短期負荷預測[J].煤氣與熱力,2006,26(12):12-15.
[6] 焦文玲,趙林波,秦裕琨.城市燃氣小時用氣負荷周期性研究[J].煤氣與熱力,2003,23(9):515-517.
[7] HASTIE T,TIBSHIRANI R,FRIEDMAR J(著),范明,柴玉梅,昝紅英,等(譯).統計學習基礎——數據挖掘、推理與預測[M].北京:電子工業出版社,2003.
(本文作者:李持佳1 劉燕2 邵震宇1 1.北京市公用事業科學研究所 北京 100011;2.北京市燃氣集團有限責任公司 北京 100035)
贊 賞 分享
您可以選擇一種方式贊助本站

支付寶轉賬贊助

微信轉賬贊助
- 注解:本資料由會員及群友提供僅供閱讀交流學習,不得用于商業用途!
